

MN4 CTE-ARM (2020) Technical details
MN4 CTE-ARM is a supercomputer based on 192 A64FX ARM processors, with a Linux Operating System and an Tofu interconnect network (6.8GB/s).
See below a summary of the system:
- Peak Performance of 648.8 Tflops
- 6 TB of main memory
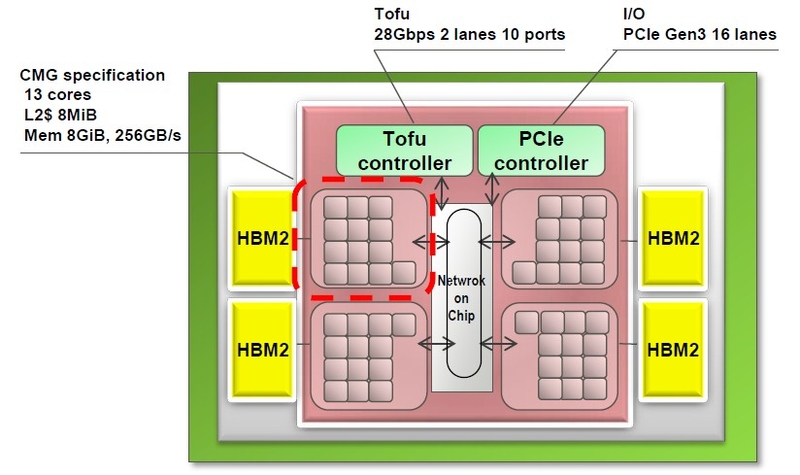
- 192 nodes, each node composed by:
- 1x A64FX @ 2.20GHz (4 sockets and 12 CPUs/socket, total 48 CPUs per node)
- 32 GiB of HBM2 1TB/s memory distributed in 4 CMGs (8GiB each socket with 256GB/s bw)
- 1/16 x SSD 512GB as local storage (shared among 16 nodes)
- Interconnection networks:
- Tofu interconnect (Interconnect BW: 6.8GB/s, Node injection BW: 40GB/s)
- I/O connection through Infiniband EDR (100Gbps)
- Operating System: Red Hat Enterprise Linux release 7.6 (Maipo)
MN4 CTE-ARM user documentation
Compute node characteristics
CORE and NUMA considerations
- A64FX, Armv8.2-A + SVE instructions set
- 52 cores in total, distributed in 4 CMGs. 48 compute cores and 4 helper cores.
NUMA distribution is as follows:
- NUMA [0-3] -> helper cores[0-3]
- NUMA [4-7] -> cores[12-23], [23-25], [36-47], [48-59]
Note: cores 4-11 are unassigned.
NODE considerations
The cluster is composed by 3 different types of nodes. All of them offer the same characteristics in terms of compute power, but differ in the connectivity and purpose. These 3 types are:
- Compute nodes: These are the more simpler ones, main SoC with provided with Tofu connnectivity between them (groups of 12 nodes).
- BIO nodes: Boot I/O nodes, nodes that contain a 512 GB M.2. 1/16 of the nodes are BIO, and serve as the boot server for all the nodes that share the same Disk.
- GIO nodes: Nodes that contain the global I/O connection to the shared file system (FEFS), as well as Infiniband EDR connection. 1/48 nodes are GIO, and serve as link to FEFS and IB for each shelf in the cluster.
Application compilation considerations
The access point for all users will be the login nodes (2 x86 intel CPUs). Due to the nature of these nodes, compilations must be done using cross-compiling, otherwise they won’t be compatible inside the compute nodes.
Most of the available applications are compiled for ARM, but some modules under the folder “/apps/modules/modulefiles/x86_64” are also available to be run in the login nodes.
Available compilers
- Fujitsu compilers (Only MPI available option):
Versions available: 1.1.18, 1.2.26b
Language Cross compilation command (from x86 login) Native ARM command Non-MPI Fortranfrtpx frtC fccpxfccC++ FCCpxFCCMPI Fortran mpifrtpxmpifrtC mpifccpxmpifccC++ mpiFCCpxmpiFCC - GNU compilers:
Versions available:- x86: 4.8.5(system), 10.2.0- a64fx: 8.3.1, 10.2.0, 11.0.0
Language Native x86/ARM compilation Non-MPI Fortrangfortan C gccC++ g++ - ARM compilers:
ARM compilers are only available from compuite nodes. These compilers are GNU based and follow the same nomenclature, but also have clang support.
Language Native ARM compilation Non-MPI Fortrangfortan/armflang C gcc/armclang C++ g++/armclang++
Fujitsu mathematical libraries and compiler options
Fujitsu provides a set of mathematical libraries that aim to accelerate calculations performed in the A64FX chip. These libraries are the following:
- BLAS/LAPACK/ScaLAPACK:
- Components
- BLAS: Library for vector and matrix operations.
- LAPACK: Library for linear algebra.
- ScaLAPACK: MPI parallelized library for linear algebra.
- Compilation options
Library Parallelization Flag BLAS/LAPACK Serial -SSL2Thread parallel -SSL2BLAMP ScaLAPACK MPI -SCALAPACK
- Components
- SSL II:
- Components
- SSL II: Thread-safe serial library for numeric operations linear algebra, eigen value/eigen vector, non-linear calculation, extreme problem, supplement/approximation...
- SSL II Multi-Thread: Supports some important functionalities that are expected to perform efficiently on SMP machines.
- C-SSL II: Supports a part of funcionalities of serial SSL II (for Fortran) in C programs. Thread safe.
- C-SSL-II Multithread: Supports a part of funcionalities of multithreaded SSL II (for Fortran) in C programs.
- SSL II/MPI: 3D Fourier Transfer routine parallelized with MPI.
- Fast Quadruple Precision Fundamental Arithmetics Library: Represents quadruple-precision values by double-double format, and performs fast arithmetics on them.
- Compilation options
Library Parallelization Flag SSLII/C-SSLII Serial -SSL2Thread parallel -SSL2BLAMP ScaLAPACK MPI -SSL2MPI
- Components
- Recommended compiling options:
Option Description -Kfast Equivalent to..
Fortran:
-O3 -Keval,fp_relaxed,mfunc,ns,omitfp,sse{,fp_contract}
C/C++:
-O3 -Keval,fast_matmul,fp_relaxed,lib,mfunc,ns,omitfp,rdconv,sse{,fp_contract} -x--Kparallel Applies automatic parallelization.
Benchmarks
The following information corresponds to some performance test runs executed "in-house" by the user support team. Information on compilation and run scripts is provided, except for HPL, which was run using a precompiled script provided by fujitsu.
HPL (linpack)
Performace score -> 548350 Gflops
HPCG
- Compilation details:
Compiler used was - fccpx: Fujitsu C/C++ Compiler 4.2.0b tcsds-1.2.26
Relevant flags defined...
CXX = mpiFCC HPCG_OPTS = -HPCG_NO_OPENMP -DHPCG_CONTIGUOUS_ARRAYS CXXFLAGS = -Kfast
- Jobscript (full cluster example):
#PJM -N hpcg #PJM -L node=192:noncont #PJM --mpi "proc=9216" #PJM -L rscunit=rscunit_ft02 #PJM -L rscgrp=large #PJM -L elapse=0:30:00 #PJM -j #PJM -S EXEC=./xhpcg module load fuji /usr/bin/time -p mpiexec ${EXEC} 80 80 80 - Scores
Compilation/Code Size Score (Gflops)Fujitsu 1 node 100 Gflops Full cluster(192 nodes) 19206.4 GflopsBSC 1 node40 GflopsFull cluster(192 nodes)7115.35 Gflops
STREAM
- Compilation details:
Compiler used was - fccpx: Fujitsu C/C++ Compiler 4.0.0 tcsds-1.1.18
Relevant flags defined...
CC = mpifccpx FCC = mpifrtpx CFLAGS = -Kfast -Kparallel -Kopenmp -Kzfill FFLAGS = -Kfast -Kparallel -Kopenmp -Kzfill -Kcmodel=large
- Jobscript :
#!/bin/bash #PJM -L node=1 #PJM -L rscunit=rscunit_ft02 #PJM -L rscgrp=def_grp #PJM -L elapse=00:10:00 #PJM -j #PJM --mpi "proc=4" #PJM -N "stream_bw" export OMP_DISPLAY_ENV=true export OMP_PROC_BIND=close export OMP_NUM_THREADS=12 mpiexec ./stream.exe - Scores
Mode Score (GB/s)Copy 839.437 GB/sScale 827.712 GB/sAdd854.164 GB/sTriad852.717 GB/s
GROMACS
- Compilation details:
Compiler used was: GCC 11.0 with fuji MPI linked libraries
Relevant flags defined..
CC = mmpifcc FCC = mpifrt LDFLAGS = "-L/opt/FJSVxtclanga/tcsds-1.2.26/lib64/" GROMACS options: -DGMX_OMP=1 -DGMX_MPI=ON -DGMX_BUILD_MDRUN_ONLY=ON -DGMX_RELAXED_DOUBLE_PRECISION=ON -DGMX_BUILD_OWN_FFTW=OFF -DGMX_BLAS_USER=/opt/FJSVxtclanga/.common/SECA005/lib64/libssl2mtsve.a -DGMX_EXTERNAL_BLAS=on -DGMX_EXTERNAL_LAPACK=on -DGMX_LAPACK_USER=/opt/FJSVxtclanga/.common/SECA005/lib64/libssl2mtsve.a -DGMX_FFT_LIBRARY=fftw3 -DFFTWF_LIBRARY=/apps/FFTW/3.3.7/FUJI/FMPI/lib/libfftw3f.so -DFFTWF_INCLUDE_DIR=/apps/FFTW/3.3.7/FUJI/FMPI/include/ -DGMX_SIMD=ARM_SVE - Jobscript :
!/bin/bash
#PJM -L rscunit=rscunit_ft02
#PJM -L rscgrp=large
#PJM -L node=1:noncont
#PJM -L elapse=2:30:00
#PJM --mpi "proc=8"
#PJM --mpi rank-map-bynode
#PJM -N gromacs
#PJM -L rscunit=rscunit_ft02,rscgrp=large,freq=2200export OMP_NUM_THREADS=6
export LD_LIBRARY_PATH=/apps/FFTW/3.3.7/FUJI/FMPI/lib/:$LD_LIBRARY_PATHmodule purge
module load fuji
module load gcc
module load gromacsmpirun mdrun_mpi -s lignocellulose-rf.BGQ.tpr -nsteps 1000 -ntomp 6
- Scores
Size Score (ns/day)1 Node 0.735 ns/day