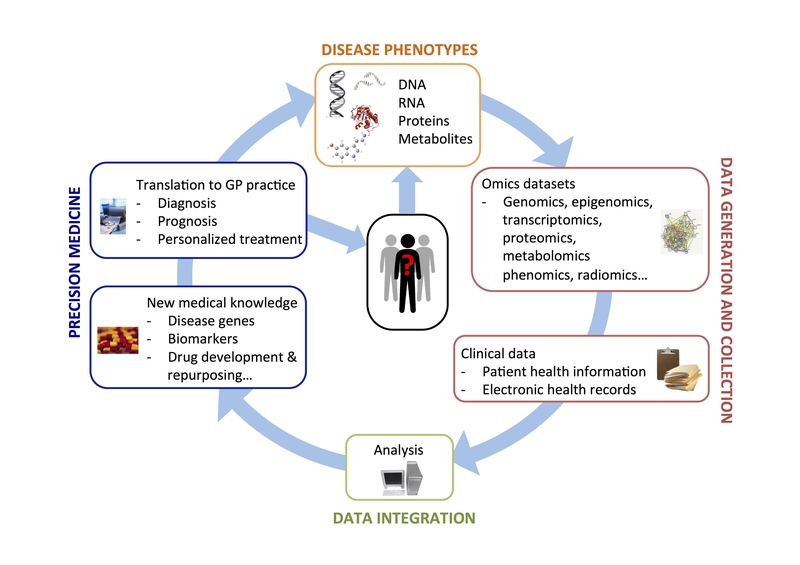
Directed by Prof. Natasa Przulj, the group is dedicated to the design of novel network science and machine learning algorithms carefully tuned to extract new biomedical information out of systems-level omics data to aid Personalized Medicine. The reason for the design of such algorithms is the wealth and complexity of versatile omic data combined with computational intractability of the posted data analytics problems.
The computational problems we address roughly fall into two main categories: algorithms for analysing single type of omics data and those for analysing multi-type related omics data collectively. The tasks of Personalized Medicine that we address by our new algorithms include patient stratification, drug, target and biomarker discovery, drug repurposing etc. The group is supported by Prof. Przulj’s ERC Consolidator grant, among other funding sources.
For further information, please see here.
Objectives
Biological Networks
Studying wiring patterns of biological networks is of great importance in our understanding of cellular mechanisms and pathology. The data comes in various forms, including networks of protein-protein interactions, transcriptional regulation, metabolism, chromatin structure, patient clinical similarities, drug-drug interactions, drug-target interactions etc. Just as analysing and aligning genomic sequences have had ground breaking impacts, network biology is emerging as a field of equal importance.
Network topology and alignment
It is the wiring patterns in these networks that are indicative of function and disease states. We design novel algorithms to mine the wiring patterns of these networks for new biological and medical information. Some of our most visible algorithms include those based on graphlets, small substructures of large networks that Prof. Przulj introduced in 2004 and that have become a basis of many algorithms for network analysis and network alignment.
Multi-scale network organization
Also, we design algorithms to mine additional biomedical information from multi-scale organization of biological systems. The need for such methods comes from the fact that proteins (and other macromolecules) rarely do things in isolation, but group together (e.g. into protein complexes and pathways) to perform a function. We model network data to capture this multi-scale organization, which we mine for new biomedical information. Some of our recent models and methods include those based on hypergraphs and abstract simplicial complexes.

Network Data Integration
Network data come in many types, as mentioned above: protein-protein interaction networks, transcriptional regulation networks, metabolic networks, chromatin structure networks, networks of patient clinical similarities, drug chemical similarity networks, drug-target interaction networks etc. These different omics networks types are measuring different aspects of the functioning of a cell or of human health. They can be seen like a different pair of glasses that we put on to look at the same phenomenon, a living cell.
It is important to extract as much biomedical information as possible from each type of data in isolation, which is the topic of our research numbered 1 above. However, all data types complement each other and the full picture of the phenomenon at study will only come from principled, integrative analyses of all data types together. This is a research line in our group and we develop integrative network analytics algorithms, including those based on matrix factorization and other machine learning approaches for data fusion.
Personalized Medicine
We develop new algorithms for improving personalized diagnostics and treatment choices. We utilize the above methods for network data analytics and fusion on versatile omics data for these purposes. We seek to uncover currently unknown disease mechanisms, prognostic biomarkers and genes driving onset and progression of complex diseases including cancer. Related research lines we are pursuing include patient stratification and prognostics, drug discovery and repurposing, disease reclassification, and Gene Ontology reconstruction.