
El nuevo modelo Matxa ya está disponible para ser testeado y ejecutado en la plataforma de IA de código abierto Hugging Face

El proyecto Aina de inteligencia artificial y tecnologías del lenguaje celebra Sant Jordi publicando el primer modelo de síntesis de voz en las principales variantes dialectales del catalán, llevando por nombre Matxa. Se trata de la primera solución tecnológica publicada como un modelo lingüístico en abierto que ofrece interpretación de texto a voz (Text To Speech/TTS) en catalán central, norte-occidental, balear y valenciano. El proyecto Aina está impulsado y financiado por la Generalitat de Catalunya.
Todos los usuarios pueden acceder al modelo disponible en Hugging Face, la comunidad de IA con recursos d’open source o código abierto, desde donde puede ser testeado y ejecutado. La tecnología desarrollada por la Unidad de Tecnologías del Lenguaje del Barcelona Supercomputing Center – Centro Nacional de Supercomputación (BSC-CNS) se entrena con diferentes datasets o conjuntos de datos, entre los cuales se encuentra Festcat, OpenSLR69 o el recientemente creado Frescat, que incluye registros en cuatro variantes dialectales y 8 hablantes diferentes.
Matxa supone un paso hacia adelante en términos de rendimiento, ya que mantiene la naturalidad y las características de las voces escogidas para entrenarlo. Para su composición, se base en la combinación de las arquitecturas Matcha-TTS y Vocos las cuales destacan por su novedad y su tiempo de ejecución muy bajos, a través de redes neuronales. El sistema de dialectos ha sido configurado y entrenado mediante el nuevo superordenador MareNostrum 5 y FinisTerrae III del Centro de Supercomputación de Galicia (CESGA).
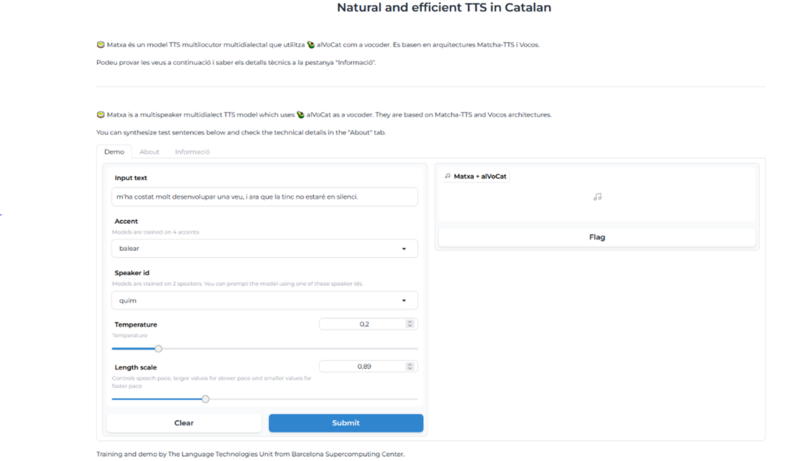
A través de la demo pública se puede probar un primer testeo del funcionamiento de Matxa:
El nuevo conjunto de datos Fescat es un desarrollo pionero en el ámbito de los recursos digitales en catalán, ya que incorpora hasta 8 hablantes con diferentes características. En total, dos voces para cada uno de los dialectos principales. El dataset se hará público en las próximas semanas y estará disponible para su descarga y uso para todos los usuarios. Para el investigador del BSC, especializado en voz, Baybars Külebi, se trata “de un recurso innovador que pone a disposición de todos, recursos digitales que tienen en consideración la pluralidad del catalán”.
El desarrollo de las tecnologías de síntesis de voz abre la puerta a un gran volumen de posibles aplicaciones. De hecho, el proyecto Aina, a través del BSC, ya trabaja con empresas e instituciones para ofrecer soluciones específicas de la mano de herramientas de inteligencia artificial desarrolladas en el centro.