
El artículo de revisión “Artificial intelligence in cancer research: learning at different levels of data granularity” de Davide Cirillo e Iker Núñez-Carpintero, del grupo de Biología computacional que dirige Alfonso Valencia, aparece en la portada del número de abril de la revista científica Molecular Oncology. En este artículo de revisión, los investigadores del BSC examinan los desafíos y las limitaciones de los enfoques de IA de vanguardia para la investigación del cáncer.
La inteligencia artificial (IA) se utiliza en una amplia gama de aplicaciones que tienen como objetivo mejorar el diagnóstico, el pronóstico y la terapia del cáncer. Por ejemplo, la FDA ha aprobado recientemente varios dispositivos radiológicos que utilizan IA para su aplicación médica en oncología. A pesar del alto rendimiento y el gran potencial para el futuro de la medicina contra el cáncer, los sistemas de inteligencia artificial están "hambrientos de datos", lo que significa que dependen en gran medida de grandes cantidades de datos para la formación. Como consecuencia, el tamaño de los conjuntos de datos que se necesitan para entrenar modelos de IA representa una de las principales limitaciones en esta área.
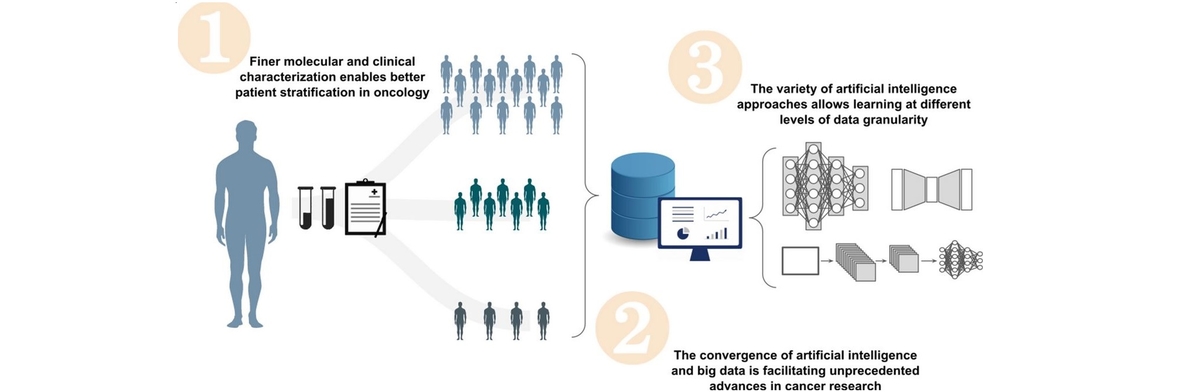
A menudo es muy difícil obtener conjuntos de datos que sean lo suficientemente grandes para entrenar modelos complejos en muchas áreas de la investigación del cáncer. Por ejemplo, los tumores pediátricos menos comunes, que afectan a un pequeño número de niños y niñas en comparación con la población general, se caracterizan por conjuntos de datos de pequeño tamaño. Sin embargo, la rareza de una condición no siempre es la razón detrás de la escasez de grandes conjuntos de datos. Por ejemplo, cuanto más desglosamos los datos por subtipos de cáncer, o simplemente por subgrupos demográficos (edad, raza, sexo), más reducimos el tamaño de los conjuntos de datos que se pueden utilizar.
Estas diferencias en la granularidad de los datos sobre el cáncer están desafiando la aplicación de la IA en oncología. De hecho, el desarrollo de soluciones de IA que permitan aprender de pequeños conjuntos de datos es un esfuerzo muy necesario, especialmente para la realización de enfoques de medicina personalizada basados en IA. En este artículo de revisión, los investigadores del BSC abordan este problema analizando los desafíos y limitaciones de los enfoques de IA de vanguardia para la investigación del cáncer. Los autores discuten varias técnicas que permiten la aplicación de la IA a pequeños conjuntos de datos, incluido el aprendizaje por transferencia, el metaaprendizaje, el aprendizaje semi-supervisado y muchos otros. Además, los autores proponen una perspectiva sobre el beneficio de implementar soluciones sinérgicas entre diferentes técnicas de IA, con especial énfasis en la generación de datos sintéticos.
Artículo: Artificial intelligence in cancer research: learning at different levels of data granularity
