

Intro
Since VASP is one of the most used applications in MareNostrum 4 and given the imminent arrival of MareNostrum 5, which will incorporate GPUs, we have tested VASP6 with CPUs and GPUs to understand how it behaves and which is the expected performance we can see depending on their input.
Build environment and software versions
VASP version: 6.3.0
Software stack (loaded modules):
nvidia-hpc-sdk/21.2
cuda/10.2
fftw/3.3.10-nvc
cmake/3.15.4
All binaries were built using the NVIDIA HPC SDK Fortran compiler with OpenMPI v3.1.5:
which mpif90
/apps/NVIDIA-HPC-SDK/21.2/Linux_ppc64le/21.2/comm_libs/mpi/bin/mpif90
mpif90 -show
nvfortran -I/gpfs/apps/POWER9/NVIDIA-HPC-SDK/21.2/Linux_ppc64le/21.2/comm_libs/openmpi/openmpi-3.1.5/include -I/gpfs/apps/POWER9/NVIDIA-HPC-SDK/21.2/Linux_ppc64le/21.2/comm_libs/openmpi/openmpi-3.1.5/lib -Wl,-rpath -Wl,/lib64:/usr/lib64:$ORIGIN/../lib:$ORIGIN/../../lib:$ORIGIN/../../../lib:$ORIGIN/../../../../lib -rpath /gpfs/apps/POWER9/NVIDIA-HPC-SDK/21.2/Linux_ppc64le/21.2/comm_libs/openmpi/openmpi-3.1.5/lib -L/gpfs/apps/POWER9/NVIDIA-HPC-SDK/21.2/Linux_ppc64le/21.2/comm_libs/openmpi/openmpi-3.1.5/lib -lmpi_usempif08 -lmpi_usempi_ignore_tkr -lmpi_mpifh -lmpi
To build the binaries, we use these base config files provided with the source code:
#CPU version
makefile.include.nvhpc
#GPU version
makefile.include.nvhpc_acc
Underlying parameters used to compile the binaries:
LLIBS += -L$(QD)/lib -lqdmod -lqd
LLIBS += -lblas -llapack
LLIBS += -Mscalapack
LLIBS += -L$(FFTW_ROOT)/lib -lfftw3
#CPU version
FC = mpif90
FCL = mpif90 -c++libs
#GPU version
FC = mpif90 -acc -gpu=cc60,cc70,cuda10.2 -cuda
FCL = mpif90 -acc -gpu=cc60,cc70,cuda10.2 -c++libs -cuda
Jobs configuration
Test 1: The first test consisted of running a primary workload on one and two full nodes, firstly using the code compiled for CPUs and then the one for GPUs (4 GPUs per node). To do that, we ran a batch of jobs like this:
[...]
#SBATCH --ntasks=4 # --ntasks=8 when used two nodes
#SBATCH --cpus-per-task=40
#SBATCH --gres=gpu:4
#SBATCH --exclusive
[...]
for i in $(ls $BINPATH); do
mpirun $BINPATH/$i/vasp_std
doneTest 2: With the second test, we wanted to see the scalability when running on just one node but using one, two, three and four GPUs.
Test 3: In the last test, we re-ran tests 1 and 2 with a higher workload.
Perfomance analysis
Results for Tests 1-2 (primary workload)
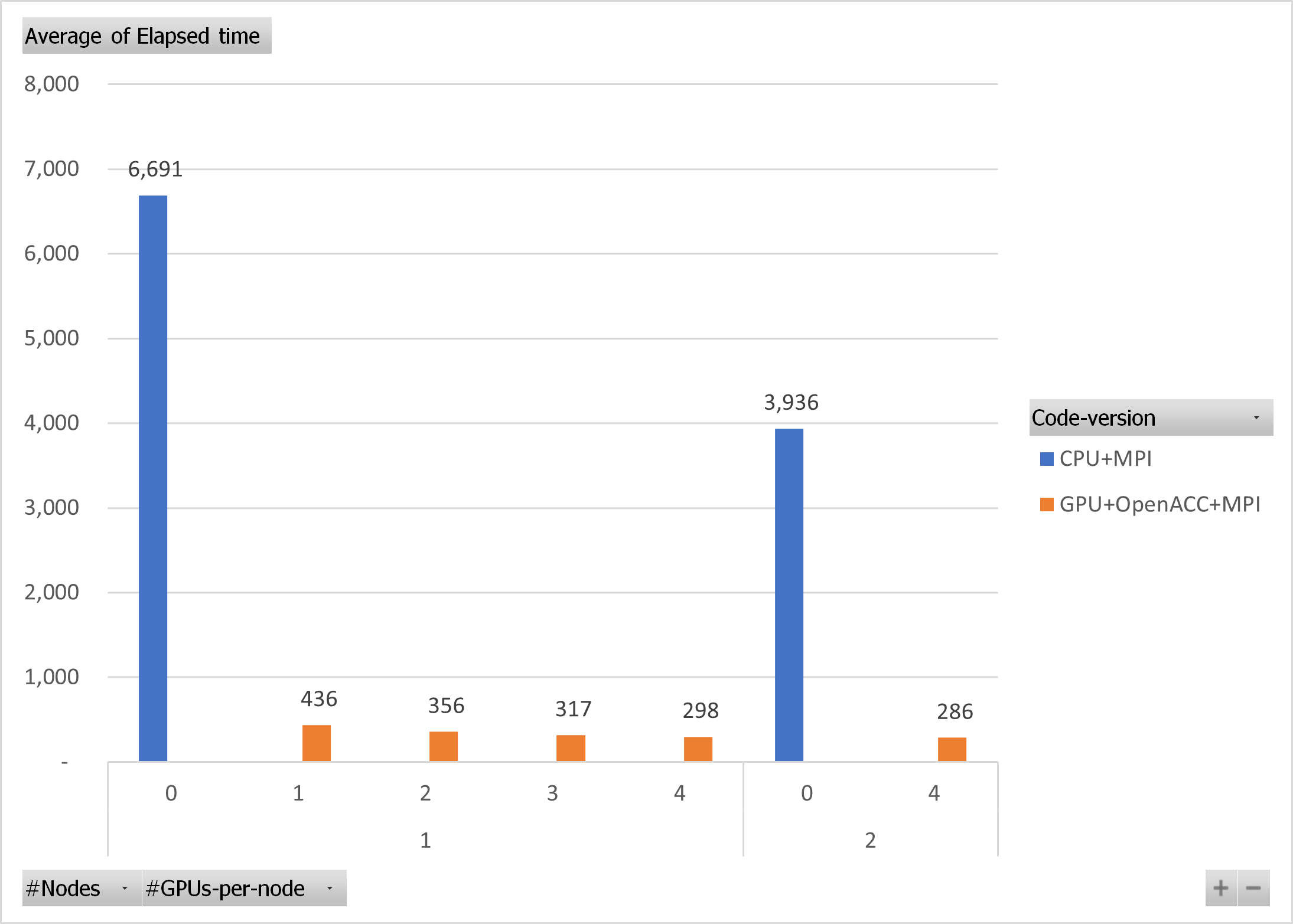
Firstly, Test 1 for the CPU code on two nodes gives us a 1.7x speedup over running on a single node. Whereas if we make the same comparison with GPU's code executions on one and two full nodes (4 GPUs per node), the gain with two nodes is a modest 1.04x. This is because this workload turns out to be very small, which is also why you only get 1.22x, 1.37x, and 1.46x over a single GPU when running on a node with two, three, and four GPUs, respectively (Test 2).
Results for Test 3 (higher workload)
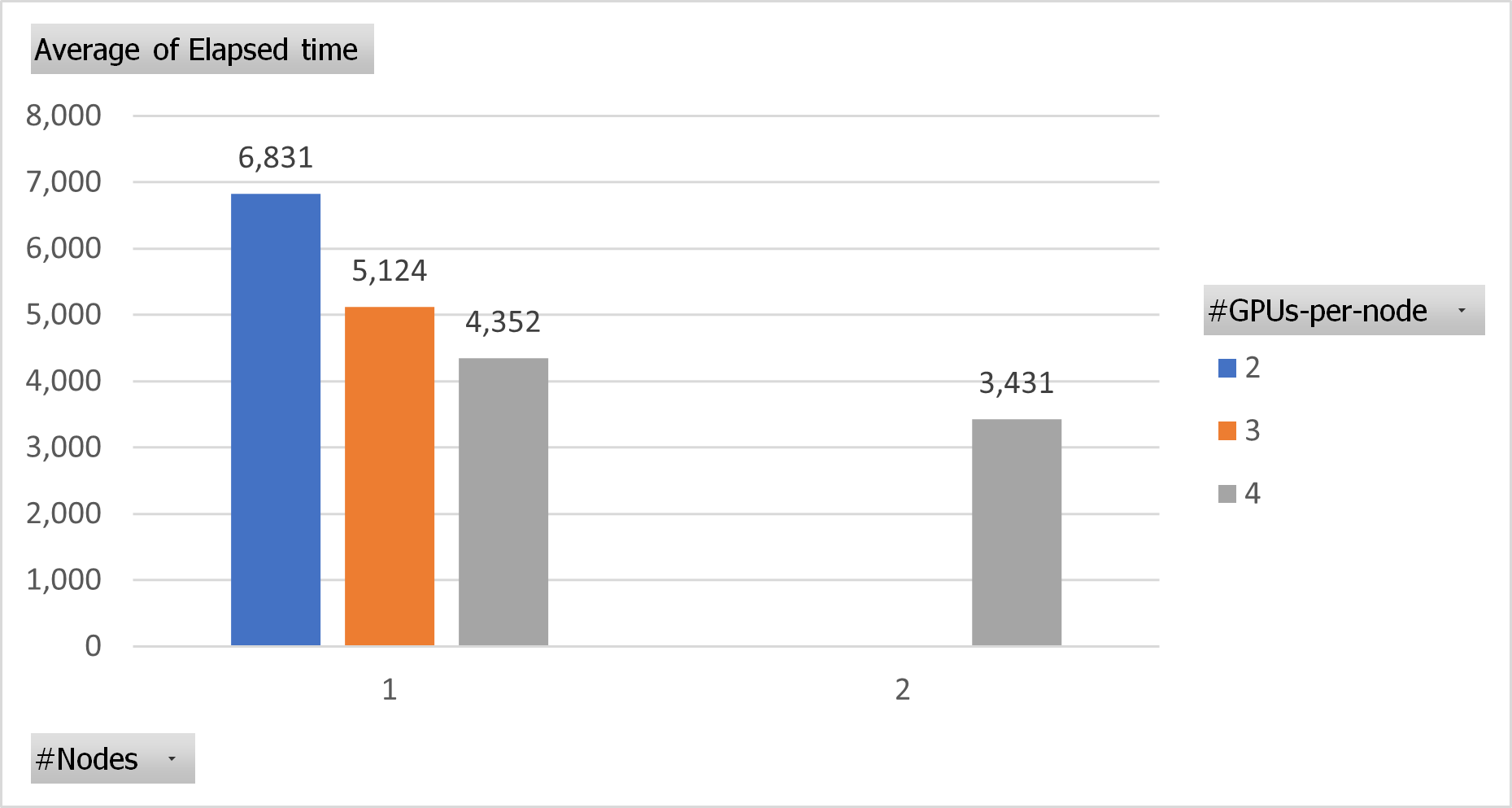
As seen in the Test 3 chart, the chosen problem size generated an execution time on two GPUs that was almost the same as when using 40 CPUs in the previous Test, but unluckily it was too big in terms of memory to test it on a single GPU (16GB). However, when observing GPU use through 'nvidia-smi', we noted that the workload did not exceed 70% in the best cases, being 50% when executing with the four GPUs using one and two nodes, as you can see below.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000004:04:00.0 Off | 0 |
| N/A 47C P0 92W / 300W | 4338MiB / 16160MiB | 59% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... On | 00000004:05:00.0 Off | 0 |
| N/A 52C P0 94W / 300W | 4332MiB / 16160MiB | 46% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla V100-SXM2... On | 00000035:03:00.0 Off | 0 |
| N/A 49C P0 88W / 300W | 4332MiB / 16160MiB | 45% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-SXM2... On | 00000035:04:00.0 Off | 0 |
| N/A 50C P0 90W / 300W | 4308MiB / 16160MiB | 48% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 71821 C ...sp.6.3.0/bin/c.GPU+OpenACC+MPI/vasp_std 4327MiB |
| 1 71822 C ...sp.6.3.0/bin/c.GPU+OpenACC+MPI/vasp_std 4321MiB |
| 2 71823 C ...sp.6.3.0/bin/c.GPU+OpenACC+MPI/vasp_std 4321MiB |
| 3 71824 C ...sp.6.3.0/bin/c.GPU+OpenACC+MPI/vasp_std 4297MiB |
+-----------------------------------------------------------------------------+
So by not using all the computing power of the GPUs, a speedup of 1.33x and 1.57x, respectively, was achieved for three and four GPUs compared to two. If we compare the execution times on one and two full nodes (4 GPUs per node), the speedup is 1.27x.
Conclusions
As you can see, for a standard workload, running on GPUs offers a noticeable performance improvement over CPU-only jobs when running on one node. The scalability in GPUs is limited, but we expect better behaviour with larger inputs like Test 3, where the scalability between 1 and 2 nodes improve compared with the Test 1 input.